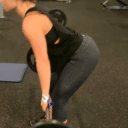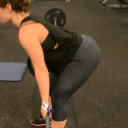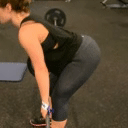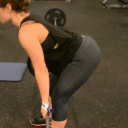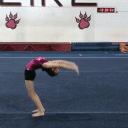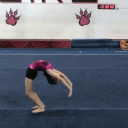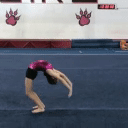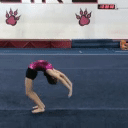MAGVIT:Masked Generative Video TransformerWe introduce MAGVIT to tackle various video synthesis tasks with a single model, where we demonstrate its quality, efficiency, and flexibility.
A single MAGVIT model is trained to perform 10 different video generation tasks. All examples in the left column are produced by the same MAGVIT model trained only on the public Something-Something-v2 dataset.
We compare different decoding methods to show the quality and efficiency of MAGVIT COMMIT decoding. We train a base transformer model with the same 3D-VQ tokenizer for each method.
Condition frames
Real videos
MAGVIT COMMIT decoding 12 steps (ours)
Autoregressive decoding 1024 steps
MaskGIT (Chang et al. 2022) MTM decoding 12 steps
Comparaing VQ Tokenizers on UCF-101
We compare different VQ tokenizers to demonstrate the superior reconstruction quality of MAGVIT 3D-VQ. These models are only trained on 9.5K training videos of the small UCF-101 dataset. See Perceptual Compression for large real-world examples of MAGVIT 3D-VQ.
Real
MAGVIT 3D-VQ (ours)
TATS (Ge et al. 2022) 3D-VQ
MaskGIT (Chang et al. 2022) 2D-VQ
Panoramic Video
Given a small vertical shot, MAGVIT can turn it into a panoramic video by applying video outpainting multiple times on both sides.
Outpaint 10 times on each side
Outpaint 5 times on each side
Image to Animation
Given a single image, MAGVIT can turn it into an animation by frame prediction, optionally with action conditions.
Stop Motion
Given two images, MAGVIT can turn it into a stop motion animation by frame interpolation.
Future Prediction
Given a single image, MAGVIT can turn it into an animation by frame prediction, optionally with action conditions.
Perceptual Compression
MAGVIT compresses a video by over 600x into a learned latent space.
We compare the original (top) and reconstructed (bottom) videos at 240p resolution.